REAL LIFE VIOLENCE DETECTION
MENTOR:
ANUGRAH SRIVASTAVA
PROJECT MEMBERS:
KOMATI NIKHILESWAR
SHASHIDHAR POLOJUADITYA SRIRAMSREYA CHEBIYYAM
JOHN VARKEY
INTRODUCTION:
Automatic recognition of violence between individuals or crowds in videos has a broad interest. In this work, an end-to-end deep neural network model for the purpose of recognizing violence in videos is proposed. The proposed model uses a pre-trained MobileNet on ImageNet as a spatial feature extractor followed by a Time Distributed layer along with Gated Recurrent Units (GRU) as a temporal feature extractor and also to extract meaningful actions from images and sequence of fully connected layers for classification purpose. The achieved accuracy is near state-of-the-art. Real-Life Violence Situations which contain 2000 short videos divided into 1000 violence videos and 1000 non-violence videos is used for fine-tuning the proposed models achieving the best accuracy of 97.0%.
PROJECT DESCRIPTION :
The Goal of the project is to classify real-life videos into Violence and Non-Violence categories. This prediction can be used combined with CCTV cameras to alert police regarding the Violence and stop the violence. This can be used along with facial recognition to identify people involved in Violence.
DATASET :
The dataset "real-life-violence-situations-dataset" is taken from Kaggle competition. The Dataset Contains 1000 Violence and 1000 non-violence videos collected from youtube videos, violence videos in the dataset contain many real street fights situations in several environments and conditions. Non-Violence videos from the dataset are collected from many different human actions like sports, eating, walking …etc.
SAMPLE VIDEOS:
MODEL USED:
PREPROCESSING:
Frames from each video are extracted using VideoFrameGenerator from Keras which extracts frames uniformly distributed over a video. These frames are used to extract features that are later used along with Time Distributed layer and GRU for extracting actions.
DATA AUGMENTATION:
The ImageDataGenerator can be used along with the VideoFrameGenerator for the purpose of data augmentation which is used to increase the dataset size as the dataset only consists of 2000 images which may lead to overfitting.
SAMPLE OF FRAMES EXTRACTED FROM VIDEOS:
TRANSFER LEARNING:
Transfer learning (TL) is a research problem in machine learning (ML) that focuses on storing knowledge gained while solving one problem and applying it to a different but related problem. For example, the knowledge gained while learning to recognize cars could apply when trying to recognize trucks.
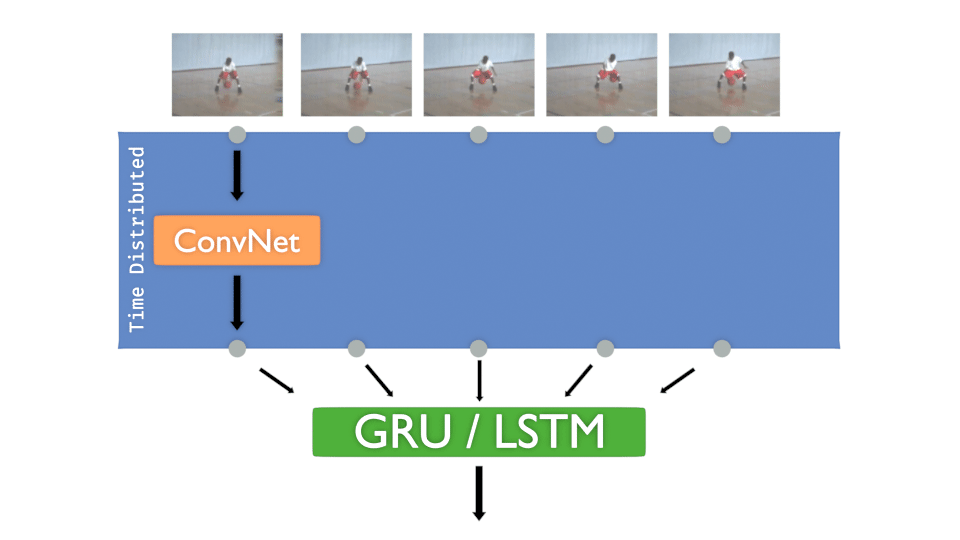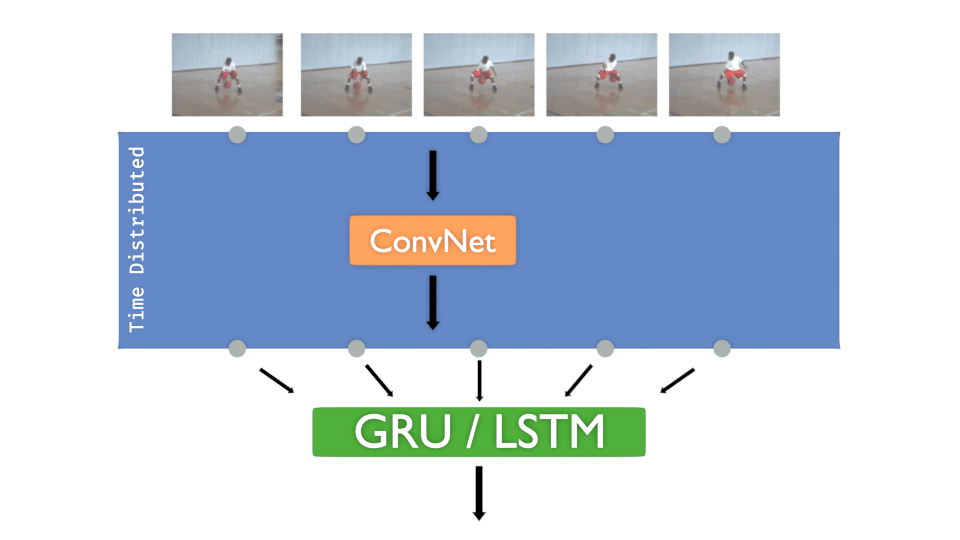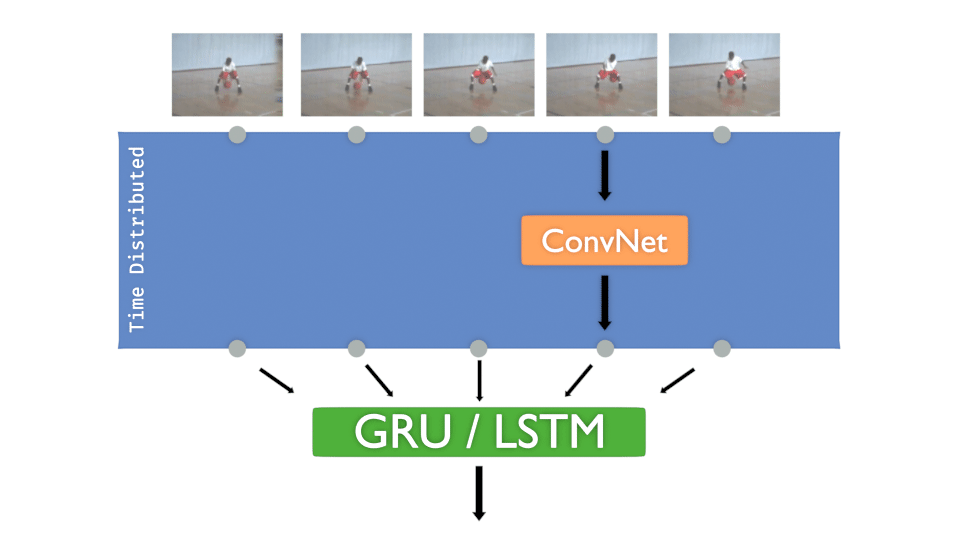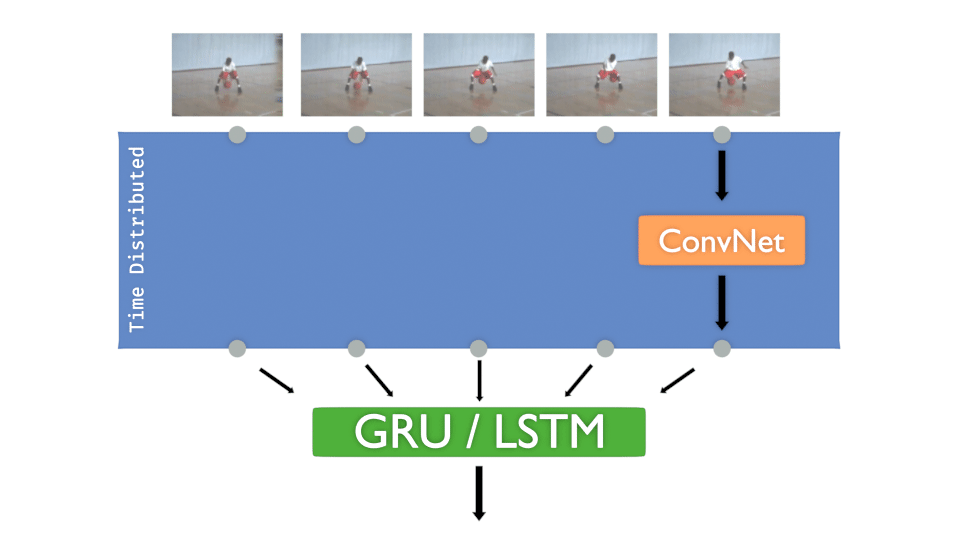
TIME DISTRIBUTED LAYER:
If you already worked with Convolution Neural Networks (C-NN), you’ve probably created models that take only one image to be classified.
But what if you need to present several images that are chronologically ordered to detect movements, actions, directions…? What we need is to be able to inject a sequence as input, and to make predictions of what that sequence is showing.
Hopefully, Keras (and other frameworks of course) provides objects that can manage that kind of data.
🔔 This is named the “Time Distributed” layer.
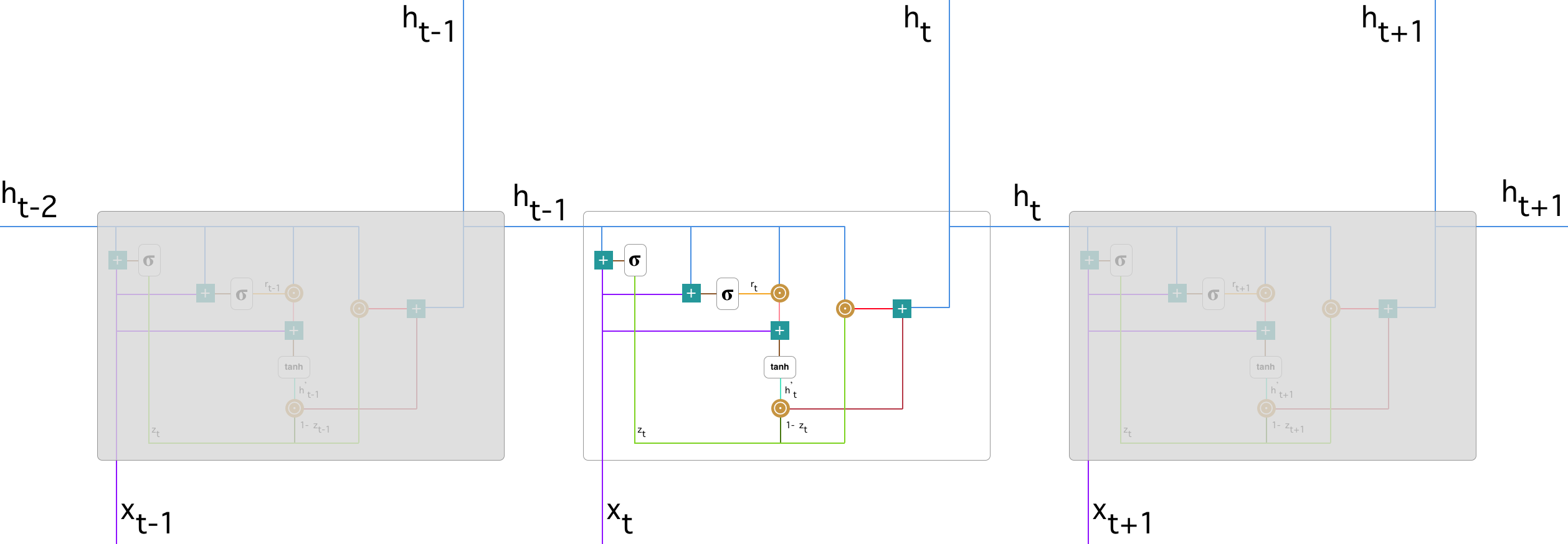
GATED RECURRENT UNITS (GRU):
GRU (Gated Recurrent Unit) aims to solve the vanishing gradient problem which comes with a standard recurrent neural network. GRU can also be considered as a variation on the LSTM because both are designed similarly and, in some cases, produce equally excellent results.
A Recurrent neural network with Gated Recurrent Unit (GRU)
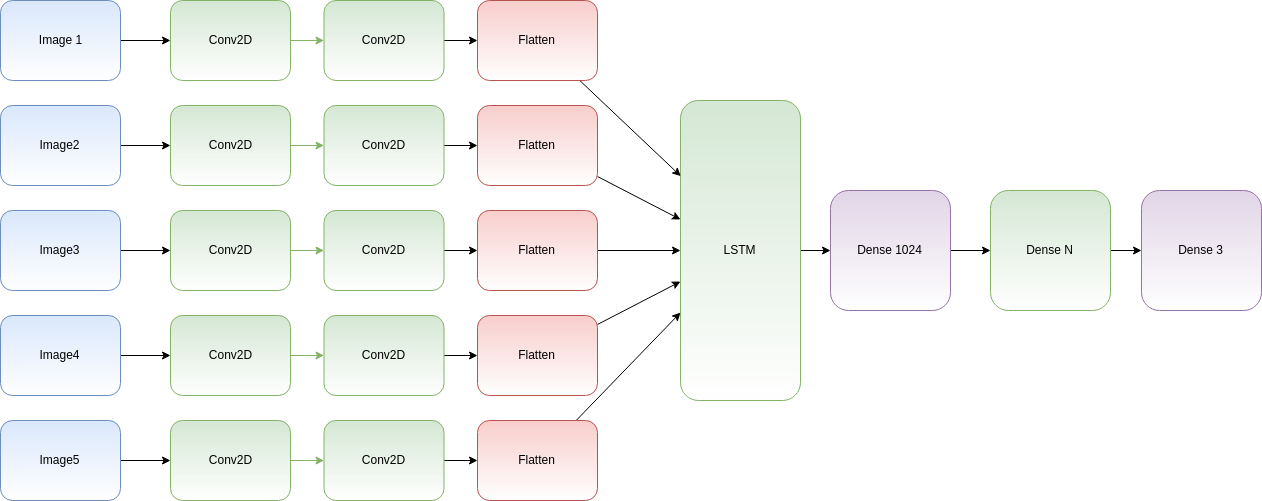
MODEL ARCHITECTURE :
Image For Representation Purpose
def build_mobilenet(shape=(224, 224, 3), nbout=2):
model = keras.applications.mobilenet.MobileNet(
include_top=False,
input_shape=shape,
weights='imagenet')
# Keep 9 layers to train
trainable = 9
for layer in model.layers[:-trainable]:
layer.trainable = False
for layer in model.layers[-trainable:]:
layer.trainable = True
output = GlobalMaxPool2D()
return keras.Sequential([model, output])
def action_model(shape=(6, 112, 112, 3), nbout=2):
# Create our convnet with (112, 112, 3) input shape
convnet = build_mobilenet(shape[1:], nbout = 2)
# then create our final model
model = keras.Sequential()
model.add(TimeDistributed(convnet, input_shape = shape))
# here, you can also use GRU or LSTM
model.add(GRU(64))
# and finally, we make a decision network
model.add(Dense(1024, activation='relu'))
model.add(Dropout(.25))
model.add(Dense(512, activation='relu'))
model.add(Dropout(.25))
model.add(Dense(128, activation='relu'))
model.add(Dropout(.25))
model.add(Dense(64, activation='relu'))
model.add(Dense(nbout, activation='softmax'))
return model
TRAINING VS VALIDATION ACCURACY :

TRAINING VS VALIDATION LOSS :
ACCURACIES OBTAINED AFTER TRAINING MODEL WITH DIFFERENT METHODS:
VGGNet: 92.81%
GoogleNet: 93.0%
ResNet: 96.79%
MobileNet: 97.0%
CONCLUSION:
We obtained the best accuracy by training the top 9 layers of the MobileNet model on top of the time distributed layer along with a GRU layer by extracting 6 frames per each video.
We have successfully beat the original model (88.2 % accurate) provided by the creators of the dataset which is published here




Comments
Post a Comment